


𝗠𝗶𝘀𝘁𝗿𝗮𝗹’𝘀 “𝑆𝑎𝑦 ℎ𝑒𝑙𝑙𝑜 𝑡𝑜 𝑚𝑦 𝑙𝑖𝑡𝑡𝑙𝑒 𝑓𝑟𝑖𝑒𝑛𝑑” 𝗣𝗶𝘅𝘁𝗿𝗮𝗹 𝟭𝟮𝗕
With Pixtral 12B, we’re looking at a smaller parameter count compared to giants like 𝐆𝐏𝐓-𝟒, 𝐰𝐡𝐢𝐜𝐡 𝐛𝐨𝐚𝐬𝐭𝐬 𝐨𝐯𝐞𝐫 𝟏𝟕𝟓 𝐛𝐢𝐥𝐥𝐢𝐨𝐧 𝐩𝐚𝐫𝐚𝐦𝐞𝐭𝐞𝐫𝐬. The real test will be how 𝐏𝐢𝐱𝐭𝐫𝐚𝐥’𝐬 𝟏𝟐 𝐛𝐢𝐥𝐥𝐢𝐨𝐧 𝐦𝐨𝐝𝐞𝐥 𝐡𝐨𝐥𝐝𝐬 𝐢𝐭𝐬 𝐨𝐰𝐧 𝐢𝐧 𝐭𝐞𝐫𝐦𝐬 𝐨𝐟 𝐩𝐞𝐫𝐟𝐨𝐫𝐦𝐚𝐧𝐜𝐞, 𝐬𝐩𝐞𝐞𝐝, 𝐚𝐧𝐝 𝐚𝐝𝐚𝐩𝐭𝐚𝐛𝐢𝐥𝐢𝐭𝐲.
𝐈’𝐦 𝐜𝐮𝐫𝐢𝐨𝐮𝐬 𝐢𝐟 𝟏𝟐 𝐛𝐢𝐥𝐥𝐢𝐨𝐧 𝐩𝐚𝐫𝐚𝐦𝐞𝐭𝐞𝐫 𝐦𝐨𝐝𝐞𝐥𝐬 𝐬𝐡𝐨𝐮𝐥𝐝 𝐛𝐞 𝐜𝐨𝐧𝐬𝐢𝐝𝐞𝐫𝐞𝐝 𝐚 𝐒𝐋𝐌 – 𝐒𝐦𝐚𝐥𝐥 𝐋𝐚𝐧𝐠𝐮𝐚𝐠𝐞 𝐌𝐨𝐝𝐞𝐥?
As far as I can tell, Mistral AI stance is that this is their latest multimodal large language model (LLM). At 12 billion parameters, Pixtral might seem small compared to models like GPT-4. But what’s exciting is how these smaller models continue to surprise us with their efficiency and speed.
The introduction of Pixtral 12B also comes with some notable updates. 𝐌𝐢𝐬𝐭𝐫𝐚𝐥’𝐬 𝐥𝐚𝐭𝐞𝐬𝐭 𝐭𝐨𝐤𝐞𝐧𝐢𝐳𝐞𝐫 𝐏𝐑 𝐫𝐞𝐯𝐞𝐚𝐥𝐬 𝐭𝐡𝐫𝐞𝐞 𝐧𝐞𝐰 𝐭𝐨𝐤𝐞𝐧𝐬: .𝐢𝐦𝐠, .𝐢𝐦𝐠_𝐛𝐫𝐞𝐚𝐤, and .𝐢𝐦𝐠_𝐞𝐧𝐝. These tokens enhance the model’s image processing capabilities, making it easier to embed and analyze visual data alongside text prompts, a interesting step forward in AI’s ability to handle multimodal tasks.
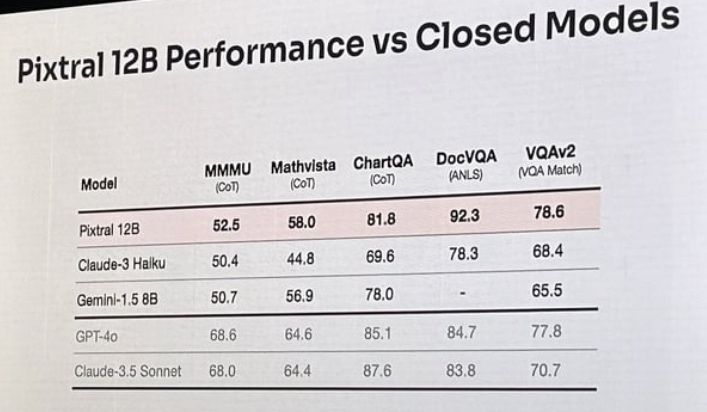
Pics from a Reddit thread. I’ll add info in the comments.
𝗡𝗼𝘁𝗶𝗰𝗲: The views within any of my posts, or newsletters are not those of my employer or the employers of any contributing experts. 𝗟𝗶𝗸𝗲 👍 this? Feel free to reshare, repost, and join the conversation.
